最近的文章

面向大语言模型的门控注意力机制:非线性、稀疏性和Attention-Sink-Free
面向大语言模型的门控注意力机制:非线性、稀疏性和 Attention-Sink-Free #

Saber:一种针对扩散语言模型的自适应加速与回溯增强的高效采样方法
Saber:一种针对扩散语言模型的自适应加速与回溯增强的高效采样方法 # Saber: An Efficient Sampling with Adaptive Acceleration and Backtracking Enhanced Remasking for Diffusion Language Model
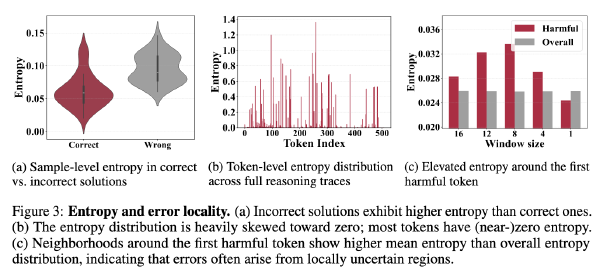
R-STITCH:用于高效推理的动态轨迹拼接
R-STITCH:用于高效推理的动态轨迹拼接 # R-STITCH: DYNAMIC TRAJECTORY STITCHING FOR EFFICIENT REASONING

真-Self-Spec-DLM
真-Self-Spec-DLM # SELF SPECULATIVE DECODING FOR DIFFUSION LARGE LANGUAGE MODELS
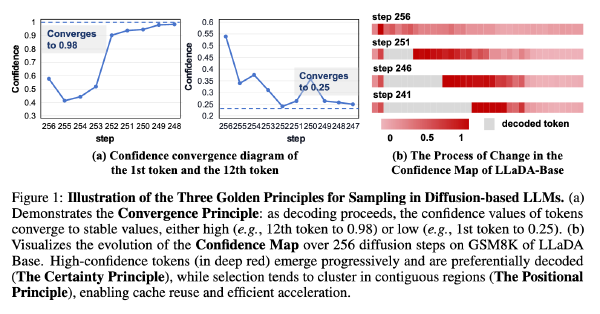
SlowFast采样加速DLM
SlowFast 采样加速 DLM # ACCELERATING DIFFUSION LARGE LANGUAGE MODELS WITH SLOWFAST SAMPLING: THE THREE GOLDEN PRINCIPLES